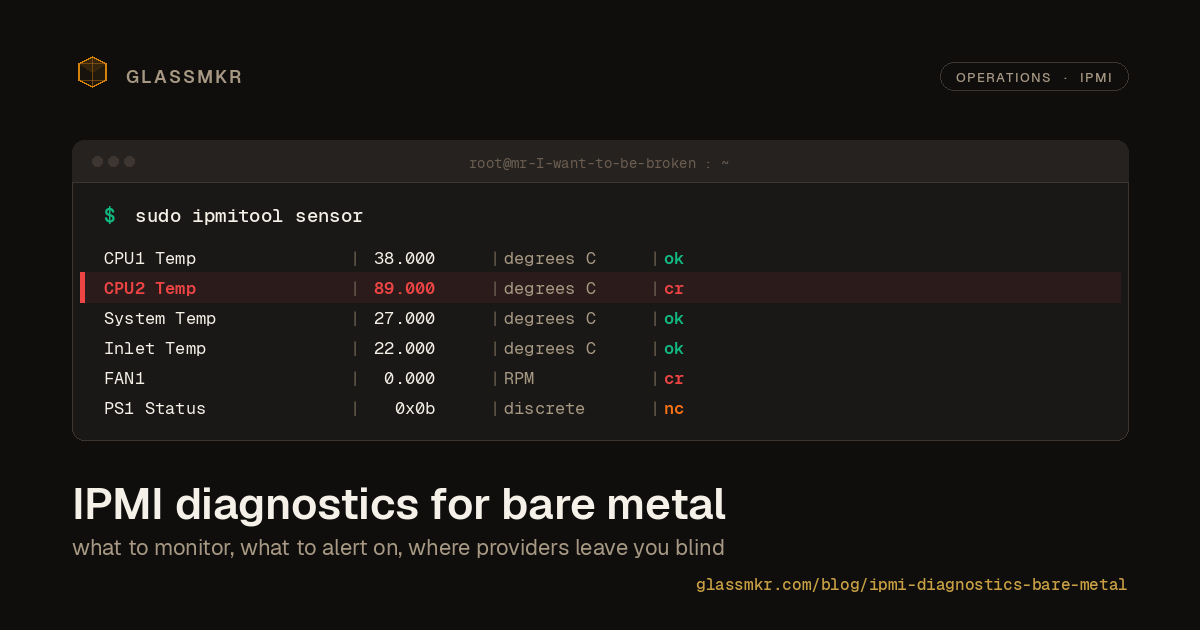
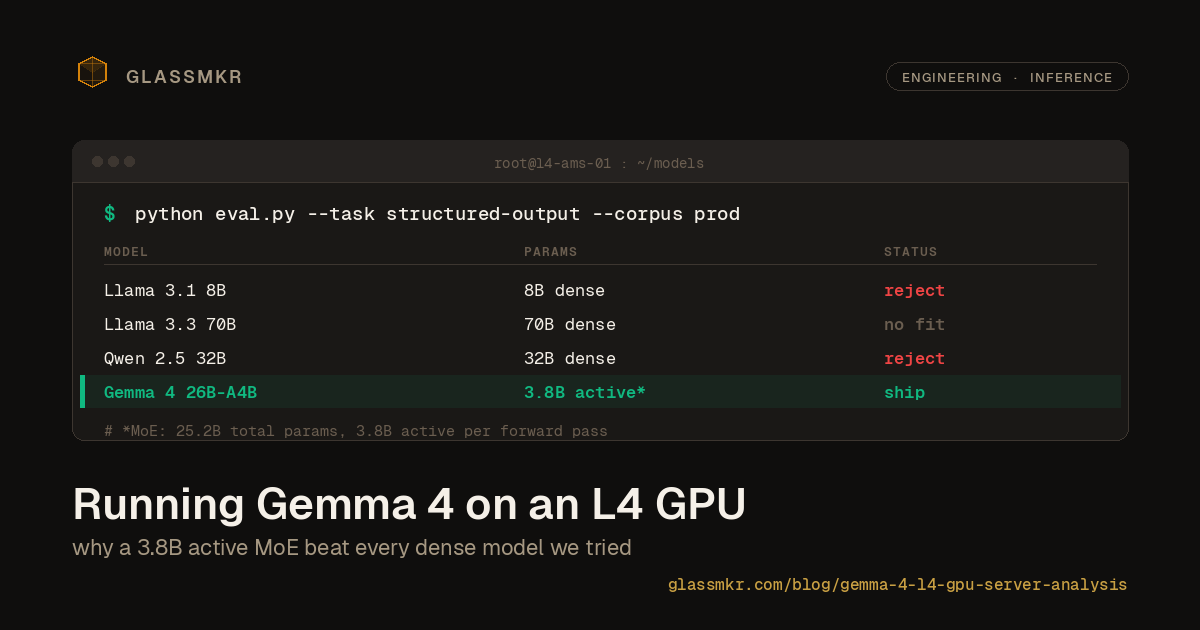
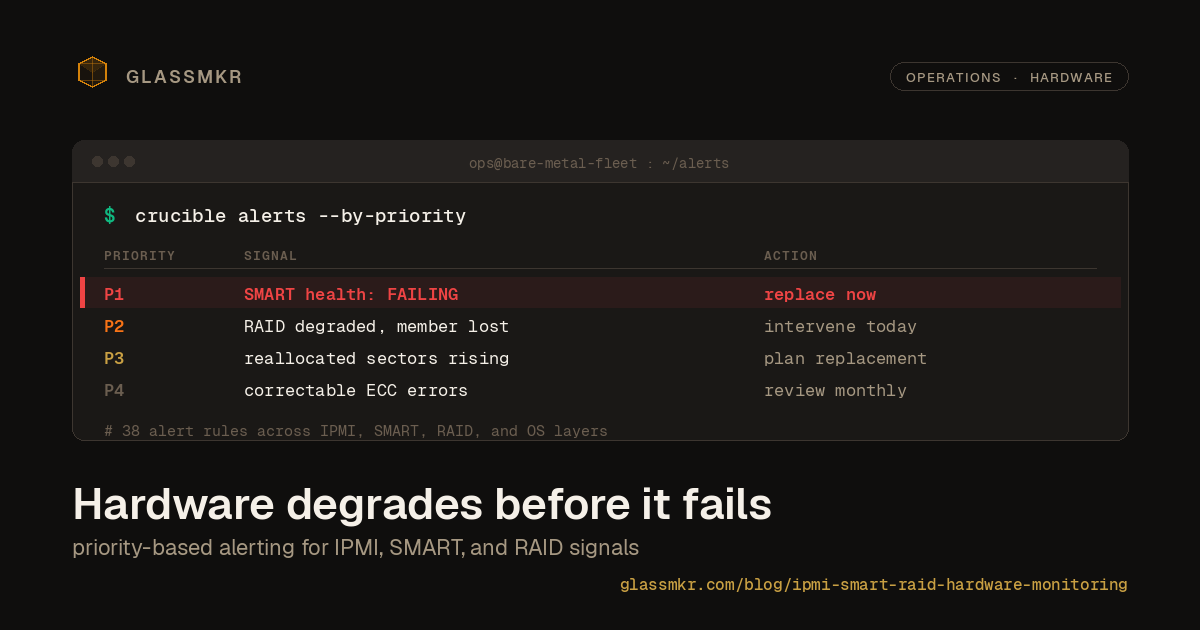
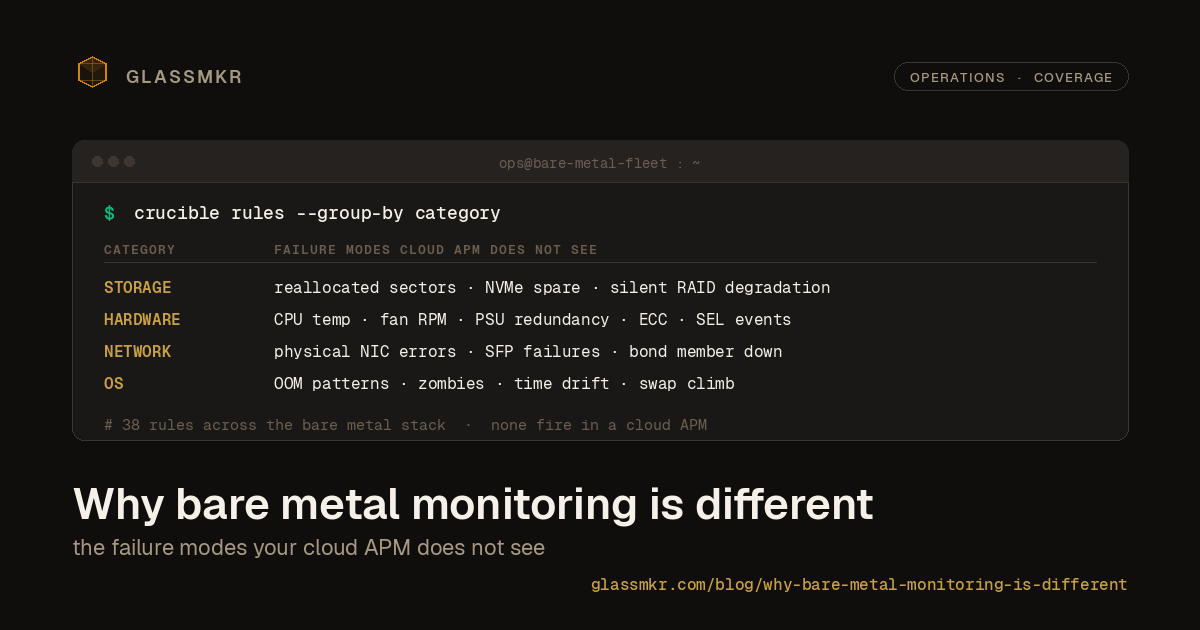
The most honest AI feature we shipped has no AI in it
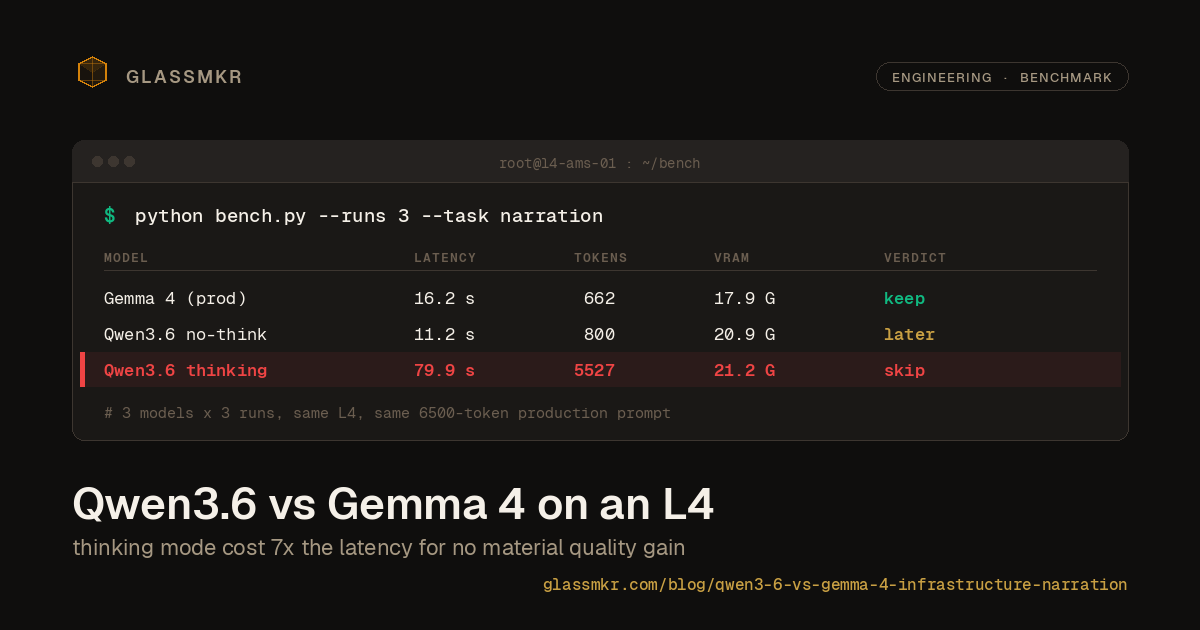
We built the self-hosted-Gemma path for our ticket-draft feature, A/B'd it against a plain template on a live degraded-array alert, and shipped the template. The model was fine. Fine did not justify 22 seconds and a hallucination surface. What we kept, what we cut, and why the value was never the prose.