Would you have caught my VRM degradation?
A customer running a Ryzen 9 5950X on a Gigabyte MC12-LE0 watched the board's VRM degrade. They asked us a fair question: would Glassmkr have caught it? The honest answer was no, not from voltage. This is what that no actually means, what we built because of it, and the moment in the backtest where we had to stop ourselves from claiming a win we had not earned.
The question
The board is an AM4 platform: a Gigabyte MC12-LE0 with a Ryzen 9 5950X. Its voltage regulator module degraded over time: the box would crash, come back, and crash again, until it could no longer power the server at all and the motherboard had to be replaced. The customer was not running us. They had collectd on the box: plenty of graphs, nothing actionable before it died. So they came to evaluate Crucible with a fair and direct question: would your tool have seen this coming?
The honest answer was no
Not from the voltage rails. There are two reasons, and neither is a bug we can patch away.
First, the CPU core rail is DVFS. VCORE and VDDCR swing continuously with load and P-state, by design. A rail that is supposed to move cannot be watched with a fixed threshold, because "the voltage changed" is its normal, healthy state, not a fault. The signal you would most want to watch for a CPU VRM is the one rail you cannot threshold.
Second, on many boards the core rail is not even a first-class sensor. It is reported as a bare value with no nominal, or it is not exposed to the BMC at all, which is the only thing an in-band agent can read. You cannot trend what the firmware will not show you.
So we said no. Voltage telemetry alone would not have caught that specific VRM degradation. We would rather say that plainly than imply a capability we do not have.
What we did have, and why it was not enough
We already ship a rail signal called psu_rail_out_of_spec. It measures point-in-time deviation: how far a rail sits from its nominal right now, as |current - nominal| / nominal. It is useful, and it has scars. The thresholds are where they are because earlier, tighter ones drowned us in false positives: a 2% trip fired constantly, well inside both the ATX plus-or-minus 5% spec band and the plus-or-minus 1 to 2% accuracy floor of a typical BMC sensor. We widened it to tiers (8% high, 5 to 8% medium), carved out a looser band for the plus-5V standby rail (regulated loosely, idles high by design), and excluded CMOS coin-cell sensors entirely after a value-range heuristic once assigned a 3.3V nominal to a healthy 2.5V rail and paged a fake 24% drift.
That is texture, not the main act. The main point is what this signal cannot do: it only speaks once a rail is already near or past spec. It says nothing about a healthy-looking rail that is slowly walking somewhere bad. The slow walk is exactly the shape of analog degradation, and it is exactly what we were missing.
Two signals, both self-baselined
Rather than build a board-specific MC12-LE0 detector, we built two general signals that catch the class of failure without per-board tuning. Each one judges a host or a rail against its own history, so there are no magic numbers to maintain per platform.
The first is host_instability, a purely behavioral signal that needs no sensors at all. It reads the snapshot stream itself. A "gap" is a stretch where a host stops reporting for much longer than its own median cadence (ten times the median, floored at 15 minutes, so a quick planned reboot is not a gap). It fires only when a previously-stable host shows two or more gaps clustered in the recent window at a rate well above its own baseline. The reasoning: a board whose power delivery is failing tends to crash, get power-cycled, recover, and repeat before it dies for good. You can see that pattern in the availability timeline even when you cannot see it in the voltage.
The second is psu_rail_voltage_drift, and it is the one worth slowing down for.
The technical centerpiece: you cannot alert on "the rail moved"
The naive version of a drift detector says "warn me when a rail's average moves." On a DVFS rail that fires every time the workload changes. The fix is to measure the move in units of the rail's own noise. psu_rail_voltage_drift compares a rail's mean over the recent window to its mean over its own baseline, expressed in standard deviations of that baseline. A fixed rail that has quietly walked three sigma away from where it has always sat is interesting. A rail that wobbles a volt either way all day, nudged a little, is not.
So the trigger has two gates, and a finding has to clear both:
// triggers.ts: a fixed rail only warns when it has walked away from its
// OWN baseline by more than its own noise band, and by a real fraction.
for (const d of features.voltage_drift ?? []) {
if (d.drift_pct < VDRIFT_PCT_FLOOR) continue; // < 1.5% of nominal: ignore
if (d.z_score < VDRIFT_Z_FLOOR) continue; // < 3 baseline sigma: ignore
// ... otherwise emit psu_rail_voltage_drift
}A rail that swings by design carries a large baseline sigma, so a mean nudge can never clear the three-sigma gate. That is the property that lets the same code watch a flat 12V rail closely while ignoring a busy core rail, with no list of which rails are which. We pinned it with a deliberately nasty test:
// A 12V rail swinging 11.0-13.0V (baseline sigma ~1.0V), with its recent
// mean nudged up to 12.3V. The 2.5% mean shift clears the percent floor,
// but 0.3V is only ~0.3 sigma, so the variance gate keeps it silent.
{ name: "P_12V", baseline: (i) => (i % 2 ? 13.0 : 11.0),
recent: (i) => (i % 2 ? 12.6 : 12.0) }
expect(v.drift_pct).toBeGreaterThanOrEqual(0.015); // clears the percent floor
expect(v.z_score).toBeLessThan(3); // fails the variance gate
expect(voltageDriftTriggers(...).length).toBe(0); // result: no warningA 2.5% mean shift would trip a naive percent threshold. Against the rail's own one-volt noise band it is a third of a sigma, and the signal stays quiet. That is the whole idea in one fixture.
The backtest, and the part where we had to be honest
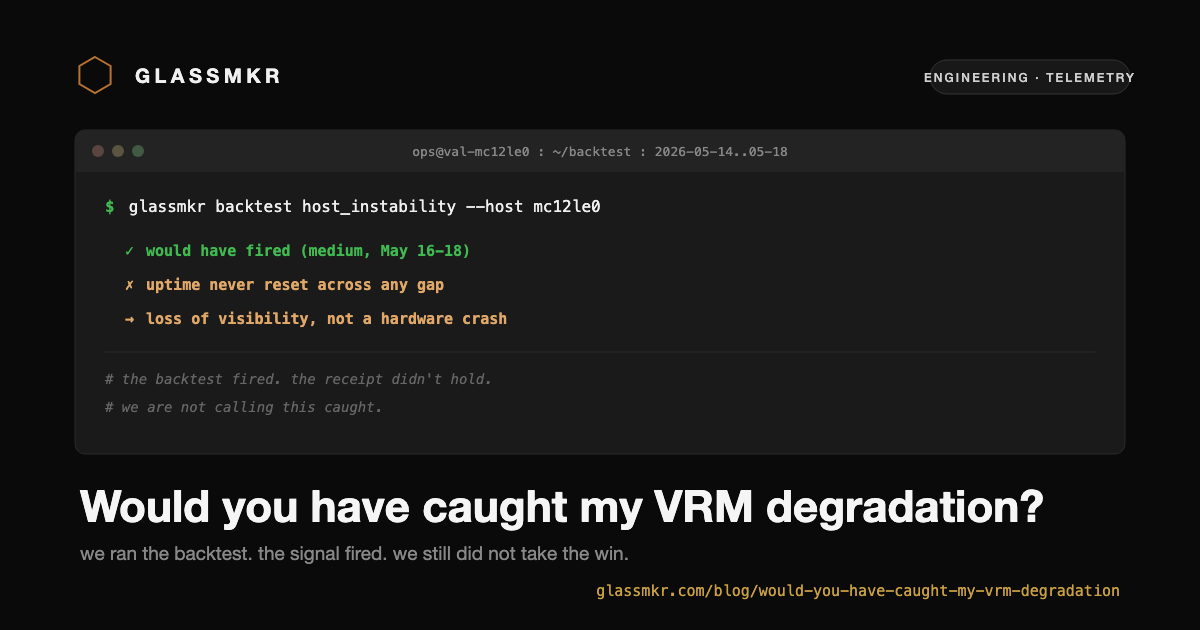
A signal you have not run against real failure data is a hypothesis. We still had the snapshot history for our own validation MC12-LE0, the same board family as the customer's, so we ran the real host_instability code against its real 27-day tape to see what it would have done.
It fired. At medium, continuously from May 16 through May 18, on a genuine cluster of multi-hour disappearances (an 11.8-hour gap, a 2.25-hour gap, and a 16-hour gap inside four days). This is the exact text the shipped code produced:
Host stopped reporting 2 times in the last 3 days (gaps over 50 min;
longest 960 min), versus 1 in the prior 8 days. Repeated unexplained
disappearances on a previously-stable host commonly precede a permanent
hardware failure (power delivery, PSU, RAM, or thermal).It held quiet on a single 40-minute blip (below the cadence-derived 50-minute gap threshold), only escalated once a second long gap clustered into the trailing three days, and cleared on its own after the box settled. The behavioral mechanics worked exactly as designed. It would have been very easy to stop writing here and call it a receipt.
So we checked one more column: uptime_seconds. If those gaps were the VRM crashing and power-cycling the box, uptime would reset to near zero on each recovery. Here is what it actually did across the three gaps:
gap (UTC) length uptime before -> after reboot?
May 14 21:28 - May 15 09:18 11.8 h 31.2 h -> 43.1 h no (+11.8 h)
May 15 17:49 - May 15 20:04 2.25 h 51.6 h -> 53.8 h no (+2.25 h)
May 17 18:47 - May 18 10:48 16.0 h 100.5 h -> 116.6 h no (+16.0 h)Uptime climbed by exactly the length of each gap. The box never rebooted. It stayed powered and running the whole time; only the agent or the network stopped reporting. Those gaps were a loss of visibility, not a hardware crash, and definitely not the VRM. Our own MC12-LE0 has zero reboot-gaps in its entire history.
So the honest verdict is split. The signal fired on real clustered outages, with real code, on real data. But on this box those outages were the agent or the network dropping out, not the failure we were chasing. We do not have a VRM crash in our own tape, and dressing a reporting outage up as a caught hardware failure would be the same dishonesty as the silent false-negative we wrote about last time, just pointed the other way.
What the backtest actually taught us
The finding's own wording gave it away: it claimed the gaps "commonly precede a permanent hardware failure." Here the hardware was fine. host_instability does not detect failing hardware; it detects loss of visibility, which is hardware-down or agent-down or network-down. Those are different incidents with different fixes, and the signal as written conflated them.
The discriminator is sitting right there in the data, which is the whole point of this post: uptime_seconds. If it resets across the gaps, the box rebooted, and a cluster of reboots on a previously-stable host is the crash-loop that really does precede a dead board. If it climbs straight through, the box stayed up and you have lost a monitoring path, not a machine. Correlating uptime lets the signal say which, instead of guessing the scary one. That is the improvement this backtest surfaced, and it is the next change going into host_instability. And it is not hypothetical: the customer's board did exactly that, crash-looping until the VRM could no longer power it and the motherboard was replaced. We could not watch it happen, because they ran collectd and not us, but a host rebooting its way to a dead board is the case the uptime check is built to confirm, and the opposite of what our own MC12-LE0's reporting gaps turned out to be.
How these route
Neither signal pages on a hunch. Both flow through the same pipeline as every other trend warning: severity drives urgency (high notifies, medium is a dashboard signal), and a finding has to persist across two evaluation batches before it can notify at all. A slow voltage drift is the opposite of urgent, so it is deliberately not in the immediate-notify set. The point is graduated confidence, not a louder alarm.
The honest close
Voltage alone would not have caught that VCORE VRM, because the rail you need to watch is the one that is supposed to move and is often not even exposed. The behavioral signal catches the consequences of a dying board, the crash-and-recover loop, and once we wire in the uptime check it will be able to tell that loop apart from a host that merely went quiet. The drift signal closes the gap for every fixed rail we can read reliably, by watching each one against its own noise instead of a spec sheet. Two complementary, self-baselined signals beat one board-specific hack.
And the part we are proudest of is the part where the backtest fired and we did not take the win. A vendor that checks its own receipts, and tells you when one does not hold, is the only kind you should trust to watch your hardware. The alert rules are public at /docs/rules, and if you want more of how the sensors themselves lie to us, that is a whole other post.