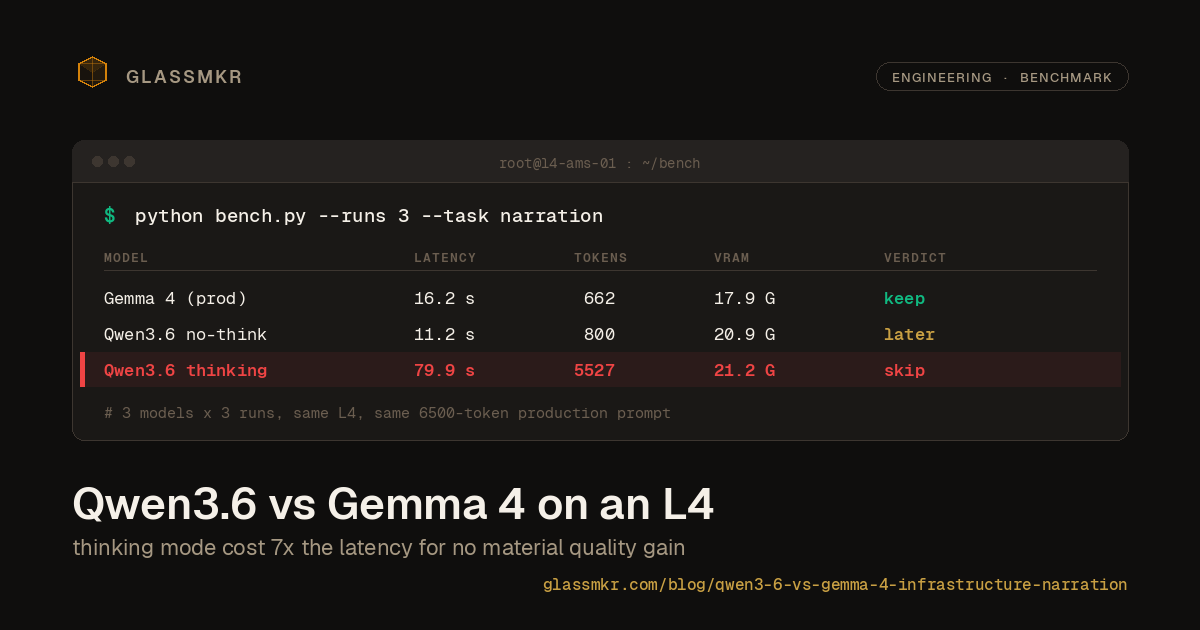
We benchmarked Qwen3.6 against our production Gemma 4 on an L4. Here's what actually mattered.
Glassmkr's Crucible agent ships a snapshot every 60 seconds: CPU load, SMART health, IPMI sensors, network errors, security posture, IPMI SEL, ZFS state, systemd failures. Furnace (our self-hosted Gemma 4 inference on an NVIDIA L4 in Amsterdam) turns that snapshot into a plain-English reading of what an operator should care about, in JSON. Today (May 2026), Furnace surfaces a verdict prior (recoverable, investigation, or vendor-side) on every alert. This is Integration 1, shipped 2026-05-20. Per-snapshot LLM narration ships in Integration 2 after 2 to 4 weeks of priors-only usage data; the pipeline this post describes is Integration 2's pipeline. Current production model is gemma-4-26B-A4B-it-UD-Q4_K_XL.gguf. Qwen released Qwen3.6-35B-A3B in late April, so we benchmarked it against our production setup. Same L4, same 6500-token production prompt, three runs each, temperature 0.3.
If you run infra and you're choosing between small MoE models for narration tasks, the results below might save you a weekend.
Setup
The prompt is real: 4154-char system prompt describing the role (senior bare metal operator), output schema, safety warnings for dangerous recommendations, analysis rules ("bond interface drops with active firewall are firewall blocks, say so"), and a strict ban on em-dashes. The user message is a 14983-char JSON snapshot from a production GPU host. Total: ~6500 prompt tokens. The response target is structured JSON with summary, findings[], optimizations[], risk_level.
Three configurations on the same llama-server binary, cold-start before each batch of runs:
| Config | Model | Flags | ctx | max_tokens |
|---|---|---|---|---|
| Gemma 4 (production) | gemma-4-26B-A4B-it-UD-Q4_K_XL.gguf | (none) | 16384 | 4096 |
| Qwen3.6 no-think | Qwen_Qwen3.6-35B-A3B-Q4_K_M.gguf | --reasoning-budget 0 | 16384 | 4096 |
| Qwen3.6 thinking | Qwen_Qwen3.6-35B-A3B-Q4_K_M.gguf | default | 32768 | 16384 |
Why three columns instead of two: Qwen3.6's thinking mode immediately truncated at our production max_tokens=4096 cap. The reasoning chain alone consumed 12K-30K characters. To fairly evaluate thinking-mode quality we had to bump both context and output limits. --reasoning-budget 0 is the clean way to turn thinking off and get the model to answer on token one, matching what the production budget can actually serve.
Results
| Metric | Gemma 4 | Qwen3.6 no-think | Qwen3.6 thinking |
|---|---|---|---|
| Valid JSON | 3/3 | 3/3 | 3/3 |
| TSA vulnerability identified | 3/3 | 3/3 | 3/3 |
| Microcode update recommended | 3/3 | 3/3 | 3/3 |
| Zombie process noted | 3/3 | 3/3 | 3/3 |
| Bond0 drops noted | 3/3 | 3/3 | 3/3 |
Correct risk_level | 3/3 | 2/3 | 3/3 |
| Em-dashes across all runs | 0 | 0 | 0 |
| Findings avg | 3.33 | 3.67 | 3.67 |
| Wall-clock (avg) | 16.2 s | 11.2 s | 79.9 s |
| Completion tokens avg | 662 | 800 | 5527 |
| Reasoning tokens avg | 0 | 0 | 19173 |
| Peak VRAM | 17.9 GB | 20.9 GB | 21.2 GB |
| VRAM headroom (24 GB L4) | 4.7 GB | 1.6 GB | 0.8 GB |
Qwen3.6 with reasoning turned off is 30% faster than Gemma with equivalent correctness on the four things that mattered: identifying the unmitigated TSA kernel vulnerability, flagging the bond0 drops as firewall noise rather than hardware (our prompt explicitly tells the model to make that call), catching the single zombie process, and recommending a microcode update for the CPU.
The one material difference: Qwen no-think returned risk_level: "healthy" once out of three runs when the snapshot had an active warning-level alert. That's technically wrong, but it's a prompt patch, not a model limitation.
Thinking mode produced 19K characters of chain-of-thought for 80 seconds of wall-clock, concluded with findings that were basically the same as the no-think version, and used 21.2 GB of VRAM leaving 0.8 GB for everything else. The quality uplift was not worth 7x the latency.
What happened in each run
Reading the actual JSON output carefully, three observations that the headline table doesn't capture:
Both models hallucinated the TSA acronym. This is worth naming clearly because it's a real risk for production narration. The server's active alert is an unmitigated AMD TSA vulnerability (Transient Scheduler Attack, publicly disclosed August 2025). Across the 9 runs:
- Gemma called it "TSX Asynchronous Abort" in all 3 runs (wrong; that's an Intel vulnerability with different mechanics)
- Qwen no-think called it "Transcendental State Access" (run 1), "Transcendental State Attack" (run 2), and "Transcendence Speculative Attack" (run 3). Three different wrong expansions in three runs.
- Qwen thinking got it right in run 3 ("TSA/TAA CPU vulnerability") but hedged in runs 1 and 2.
Neither model was trained on enough data about AMD TSA to know what the acronym stands for. Both produce confident-sounding expansions anyway. The validator layer in our broader design rejects exactly this class of output, an acronym expansion that isn't grounded in the input JSON, but a less disciplined narration pipeline would ship these hallucinations to users. Worth knowing before you trust a small MoE to narrate anything with a recent technical term.
Qwen no-think's content is more analytically useful, Gemma's is more reliably on-schema. On bond0 drops, Gemma says "transient buffer event" or "driver-level buffer event." Qwen says "occurring at the bond aggregation layer, which is consistent with UFW dropping packets before they are handed to the underlying interfaces." Qwen's explanation is better because the prompt specifically told the model to make that call, and Qwen actually makes it. On the IPMI SEL "Unknown #0xff" noise, only Gemma run 3 notices the pattern. Qwen no-think runs 2 and 3 identify it as "BMC firmware quirk" or "sensor mapping artifacts", correct operator-grade reading.
Counterweight: Qwen no-think run 2 returned risk_level: "healthy" despite the warning-level alert. The chain of reasoning (visible in the completion) argued that TSA is "low risk in most non-hostile environments" and walked the severity down. That's not a model limitation per se, but it means Qwen is more willing to exercise judgment against the input signals than Gemma, for better and worse. Gemma's 3/3 "watch" is more conservative and in this case more correct.
Thinking mode's "better" finding wasn't actually reasoning. Qwen thinking run 1 correctly returned risk_level: "warning" where the no-think runs used "watch." Reading the 12,870 characters of chain-of-thought that produced this: the model reasoned "the alert is warning, so risk is warning." That's a correct mapping and it's also a one-line prompt fix, not a reasoning breakthrough. The other 79 seconds of thinking added nothing the no-think runs didn't already produce.
The em-dash question
Glassmkr's system prompt forbids em-dashes. Both models complied across all 9 runs. This matters because the em-dash is the single most common LLM output tell in written material. Ban it, and the narration reads like a human operator wrote it. Ban it and verify, because we've seen models ignore the rule on longer outputs.
What worked: explicit, terminal in the system prompt ("Never use em-dashes. Use commas, semicolons, colons, or periods.") near a section about output format. What hasn't worked in earlier tests: a softer instruction ("avoid em-dashes") buried in general guidelines.
Recommendation for this workload
We're staying on Gemma 4 for production, with Qwen3.6 no-think as the switch candidate when we revisit the tradeoff. Four reasons:
VRAM headroom. Production snapshots can be 5-10x larger than the test snapshot (more drives, more DIMMs, more IPMI sensors on high-density hosts). Gemma's 4.7 GB headroom gives room. Qwen no-think at 1.6 GB is tight; a busy snapshot plus a context extension could trigger swap or OOM.
The "healthy" miscall is a known prompt issue we can fix, but haven't yet. If Qwen produces the correct risk level after a prompt patch, the 30% latency improvement becomes worth switching for. Until then, Gemma's 3/3 correctness is the baseline.
Gemma's hallucinations on the TSA acronym are at least internally consistent (calling it "TSX Asynchronous Abort" three times with the same wrong expansion), whereas Qwen produced three different wrong expansions. Neither is ideal; both get caught by our validator layer. But Gemma's failure mode is easier to audit. Qwen's inconsistency suggests we'd want to add the actual AMD TSA definition to the system prompt before switching, to give the model a grounded reference it can quote.
Production is running fine. The model selection cost on an infra narration task is not zero. There's prompt tuning, there's reviewing outputs across a sample of real production snapshots, there's handling the switchover without breaking dashboards. Until we have a concrete reason (a snapshot Gemma consistently misreads, a context-length need Gemma can't meet, a latency budget Gemma can't serve), Gemma stays.
If any of those change, Qwen no-think is a single --reasoning-budget 0 flag away.
Thinking mode is not worth shipping for narration
This is the generalizable takeaway. Thinking mode on small MoE models trades enormous latency for marginal quality gains on tasks where the model isn't actually reasoning through novel logic. Infra narration isn't one of those tasks. The deterministic pipeline behind the narration has already done the reasoning (which metrics matter, which alerts fired, which patterns correlate). The LLM's job is to explain it. Reasoning over the explanation layer is redundant.
If your task genuinely requires multi-step reasoning (agentic tool use, complex code synthesis, mathematical proofs), thinking mode may earn its keep. If your task is "turn structured evidence into natural language," it doesn't.
The implication: don't let thinking-mode benchmarks drive your model selection for narration. A good non-thinking model on the same architecture will get you the same quality at a fraction of the compute.
Configuration for anyone replicating
Both models run under llama-server (build b8707) on a single 24 GB L4. Default flash attention, -ngl 999 to put every layer on GPU.
Gemma 4:
llama-server \
--model gemma-4-26B-A4B-it-UD-Q4_K_XL.gguf \
--ctx-size 16384 \
--n-gpu-layers 999 \
--host 0.0.0.0 --port 8000Qwen3.6 no-think:
llama-server \
--model Qwen_Qwen3.6-35B-A3B-Q4_K_M.gguf \
--ctx-size 16384 \
--n-gpu-layers 999 \
--reasoning-budget 0 \
--host 0.0.0.0 --port 8000Qwen3.6 thinking (document only; not recommended for narration):
llama-server \
--model Qwen_Qwen3.6-35B-A3B-Q4_K_M.gguf \
--ctx-size 32768 \
--n-gpu-layers 999 \
--host 0.0.0.0 --port 8000Request body:
{
"model": "[model-name]",
"messages": [
{"role": "system", "content": "<glassmkr system prompt>"},
{"role": "user", "content": "<snapshot JSON>"}
],
"temperature": 0.3,
"max_tokens": 4096
}For thinking mode, raise max_tokens to 16384 or the model will truncate before producing the final JSON answer.
What's next for Glassmkr's AI narration
The model we ship is less interesting than the discipline around it. Every narration in Glassmkr is deterministic first: the alert rules fire on current state via a rules engine, trend analysis runs separately via statistical methods, correlation rules match multi-signal patterns. The LLM only narrates what deterministic code has already concluded. If the model output fails the validator (as both models did on the TSA acronym in this benchmark), Furnace drops the offending finding rather than shipping it; the alert still surfaces with its deterministic content (rule trigger, evidence, copy-pasteable FIX). The user always sees the underlying metric values, the specific commands to verify, the corroborating evidence; what they may or may not see is the model's gloss on top.
This is why model selection matters less than most AI-monitoring marketing implies. The LLM is a narration surface, not a decision layer. Switching from Gemma 4 to Qwen3.6 would improve latency by a few seconds and might give us slightly more contextual detail in findings. It wouldn't change what Glassmkr considers a failure, why, or when.
That's how we think it should be for production infra. If you're building something similar, benchmark the small MoE models on your actual prompt with your actual data. The answer might surprise you. And whatever model you pick, build the validator first.
Two companion posts: how we got Gemma 4 running on the L4 (the deployment + quantization + prompting story behind this benchmark), and how we co-locate quarterly LightGBM training on the same L4 without disturbing Furnace inference.
Notes
Glassmkr is bare metal monitoring that catches what your hosting provider doesn't. Open source agent (@glassmkr/crucible on npm, ghcr.io/glassmkr/crucible on Docker), free for 3 servers, $3/node/month for Pro. glassmkr.com/docs.