Introducing Glassmkr: bare metal monitoring built by operators
You rented a dedicated server because you wanted control. What you got instead is a machine that only tells you it's alive by answering ping. The drive is accumulating reallocated sectors. A fan slowed down last week. The RAID array lost a member yesterday and the rebuild is stressing the surviving disks right now. Your hosting provider doesn't know. Nagios didn't ship with a rule for it. Datadog costs more than the server.
This is the gap Glassmkr fills.
What Glassmkr is
Glassmkr is monitoring for people who run their own hardware. One philosophy: collect what actually breaks physical servers, alert on the priorities that matter, and don't pretend the solution is a cloud APM that was never designed for this workload.
It is shipped as two pieces that work together or standalone.
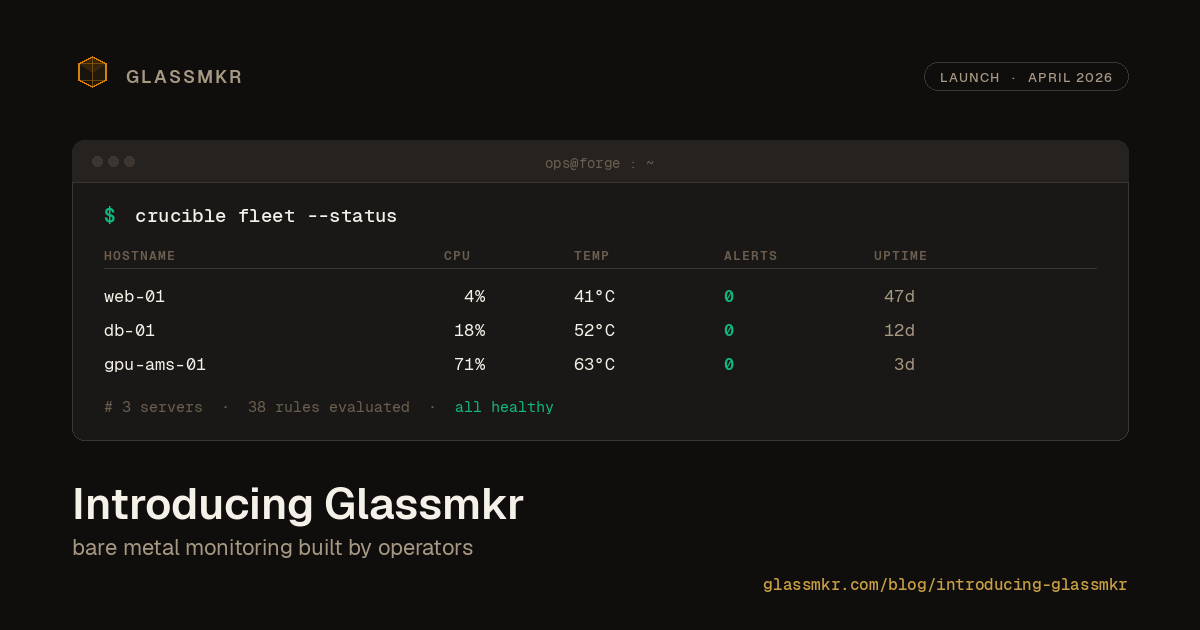
Crucible is the open-source collector. One curl | bash install. Reads from smartctl, ipmitool, mdadm, /proc, /sys. Pushes a complete health snapshot every 60 seconds. Median 91 MB RSS (range 65 to 103 MB across our 7-host validation fleet), measured at v0.13.3. No kernel modules, no eBPF, no root hooks into your application stack. Available on npm and Docker Hub. MIT licensed. Run it standalone (pipe the output wherever you want) or pair it with Dashboard. (Note: a follow-up measurement against the 0.13.6 fleet showed the figure has drifted to around 108 MB; current footprint numbers live on the docs page.)
Dashboard is the optional SaaS. It receives Crucible's snapshots, stores history, renders fleet views, and sends alerts. 62 opinionated alert rules across 9 categories: storage, ZFS, filesystem, memory and CPU, network, hardware and BMC, time and services, security and patching, and GPU. Furnace, our self-hosted Gemma 4 inference on an NVIDIA L4 in Amsterdam, surfaces a verdict prior (recoverable, investigation, or vendor-side) on every alert. This is Integration 1, shipped 2026-05-20; per-snapshot LLM narration ships in Integration 2 after 2 to 4 weeks of priors-only usage data. $3/node/month with the first 3 nodes free; if 3 servers is your whole fleet, the agent stays free forever.
Where this came from
Glassmkr is built and maintained by one operator in Prague. The day job is a decade of running bare metal infrastructure at scale on multiple continents. Every alert, every threshold, every diagnostic in the product comes from real operational experience. The 62 alert rules are not theoretical coverage. They are the things that have woken me up. The IPMI parsing handles vendor quirks because I have hit them. The RAID degradation detection fires on member loss rather than performance because that is the one you actually care about at 3 AM.
Where a parser hasn't been validated against a vendor in production, we say so. Crucible v0.13.3 emits a parser_quality field on every collector (full, partial, or stub); Dashboard surfaces stubs as a soft "not yet observed on this hardware" rather than dressing them up as production-ready. Honest gaps beat fake confidence.
I built Glassmkr over the first four months of 2026. Every feature decision, every rule priority, every dashboard layout was driven by production pain on my own infrastructure. I do not build features I have not encountered. Opinionated coverage beats configurable generality when the goal is catching real problems before they become outages.
The architecture
Your server runs Crucible as a systemd service. Every 60 seconds it gathers SMART attributes for every drive, IPMI sensor readings, RAID array state, per-core CPU (not just aggregate, the per-core breakdown that catches IRQ pinning and single-threaded saturation), memory and swap, network interface stats, filesystem state, security posture, and pending updates. It pushes this snapshot over HTTPS to Dashboard.
Dashboard evaluates the 62 alert rules against the snapshot, compares it to history, and either fires new alerts or closes resolved ones. Each alert is assigned a priority level: P1 for data loss imminent, P2 for service-impacting, P3 for degrading, P4 for informational. Alert cards include evidence links, diagnostic commands, and recent trend data. Notifications go to Slack, Telegram, or email.
Furnace runs on our own NVIDIA L4 in Amsterdam, serving Gemma 4 26B-A4B over a private WireGuard network. Your server's data never touches a third-party API. We have written separately about why we self-host the model and how we chose it; the short version is that sending IPMI sensor data and hardware serials to an external cloud to analyze whether your infrastructure is healthy is ironic.
How it was built
Glassmkr was built with heavy use of AI coding tools, primarily Claude Code. Every architectural decision, every alert threshold, every dashboard layout was made by me. The AI did the typing. I did the deciding.
Two rounds of security audit were run before launch (see /trust for details). The Crucible source is MIT licensed and short enough to read in an afternoon, which is the point. If you are skeptical of AI-assisted code in your monitoring stack, audit it. That is why it is open.
Pricing
The agent (Crucible) is MIT licensed and free. Always.
Dashboard Free covers up to 3 servers, all 62 alert rules, 7-day history, and all notification channels. If that is enough for your setup, you are done.
Dashboard Pro is $3/node/month with the first 3 nodes free. You get longer history, the AI health analysis, more notification routing options, and priority support. There is no per-metric surcharge, no alert-volume tiering, and no cloud-scale pricing math. You pay for the nodes you have, minus the first three.
Start
Install Crucible on a server:
curl -sf https://glassmkr.com/install.sh | bashThe install script registers the server with Dashboard, sets up the systemd service, and begins collecting data within a few minutes. Browse to app.glassmkr.com to see your fleet.
If you just want the agent and not the SaaS, Crucible is on GitHub and npm. Pipe its output wherever you want it.
What we are not
We are not a Datadog replacement for cloud workloads. If your infrastructure is Kubernetes on EKS, use something else.
We are not a SaaS that hides the collector in a proprietary binary. Read the Crucible source. Audit exactly what leaves your server.
We are not trying to be everything. No application performance monitoring, no distributed tracing, no log aggregation. Glassmkr does hardware and OS health. It does not pretend to be observability.
We are not a black-box SaaS you cannot escape. Crucible is MIT and works standalone without Dashboard. If Glassmkr ever shuts down, your agent and your data stay yours.
What is shipped recently, what is next
Shipped since launch: GPU monitoring (8 rules covering XID errors, ECC counters, PCIe link state, thermal trip, power-cap throttling, NVLink, and driver drift; validated on NVIDIA L4, RTX A4000, and A16). Trend-based alerting (the largest in-flight feature when this post first went out): statistical detection of reallocated-sector growth, fan-speed drift, and disk-fill projection, all shipped. Cross-snapshot correlation: shipped. Furnace Integration 1 (verdict prior badges on every alert): shipped 2026-05-20.
Near-term: Furnace Integration 2 brings per-snapshot LLM narration on Pro tier, after 2 to 4 weeks of priors-only usage data. Deeper NVMe controller telemetry and hardware RAID support beyond mdadm (LSI MegaCLI, HP SSACLI, Dell PERC) are in flight.
Every addition follows the same rule: only ship alerts for failure modes we have actually encountered in production.
For operators, by operators
Glassmkr exists because the monitoring tools that worked for cloud-native teams did not work for us. We built what we needed. If you run bare metal and recognize the description above, try it. The Free tier is genuinely free. The paid tier is priced to be affordable at any fleet size.