Validating GPU monitoring across three NVIDIA cards: L4, RTX A4000, A16
Before we returned our validation fleet, we pointed the eight GPU alert rules at three different NVIDIA cards. Three of the rules we tested live on real hardware. Five we deliberately did not. This is the honest version of what "GPU monitoring, tested" actually means.
Most of our alert rules can be exercised by safely inducing the condition: fill a disk, load the CPU, fail a RAID member and add it back. GPUs are different. The faults that matter most on a GPU, an uncorrected ECC error, a critical XID event, an NVLink drop, are exactly the faults you cannot safely create on a machine you intend to keep using. A real one usually corrupts state and needs a power cycle to clear. So the interesting question for GPU monitoring is not just "does the rule fire," it is "which rules can you honestly say you tested, and how."
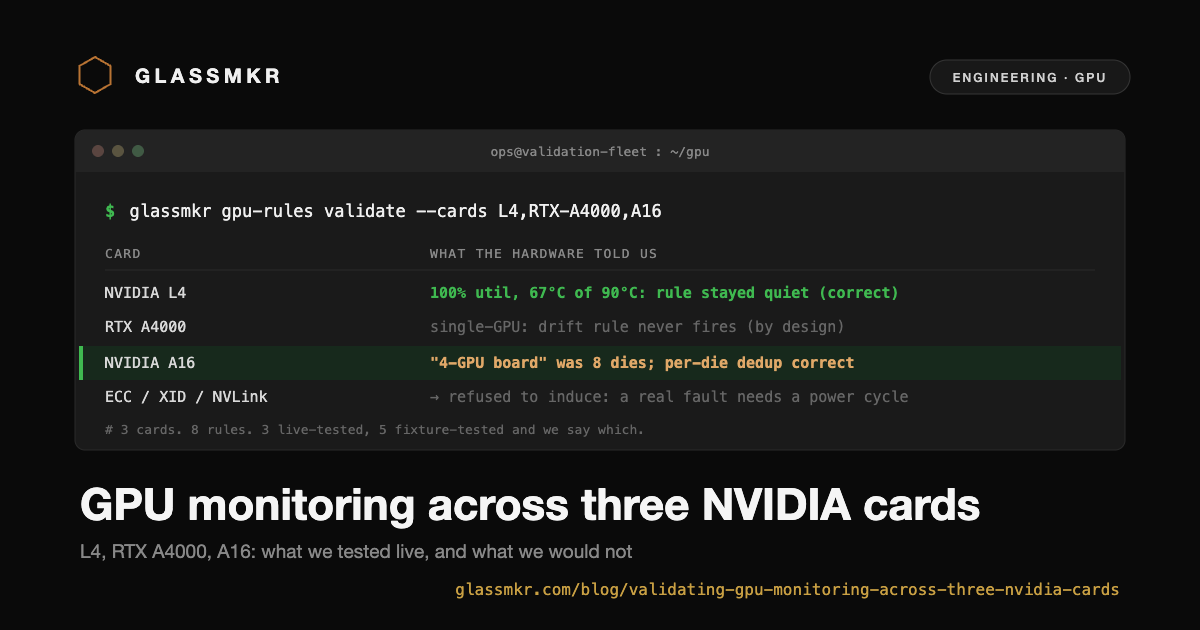
We had three cards on the fleet: an NVIDIA L4 (the same card our production inference host runs), an RTX A4000, and an A16. All three on Debian 13, driver 550.163.01. Here is what each one told us.
Three cards, eight rules
The GPU rule set is eight rules: thermal critical, power-cap throttling, corrected-ECC storm, uncorrected ECC, XID critical, PCIe link degraded, NVLink down, and driver/firmware drift. We split them into what was safely inducible and what was not, and we recorded the split explicitly rather than quietly marking everything "tested."
- Live-tested on real hardware (3): power-cap throttling (A16), thermal critical (L4), driver/firmware drift (all three cards).
- Fixture-tested, not induced (5): uncorrected ECC, corrected-ECC storm, XID critical, PCIe link degraded, NVLink down.
What we refused to induce, and why that is the honest answer
Five of the eight rules are classified synthesize-only: validated against typed test fixtures that feed the evaluator the exact shape of a real fault, but never induced on the physical card. This is a deliberate policy, not a gap we are hiding.
Real uncorrected-ECC injection corrupts VRAM and typically requires a power cycle to recover. A witnessed critical XID event implies a hardware fault that is not safely reproducible. Forcing an NVLink down risks wedging multi-GPU collectives mid-flight. PCIe link-width modification means re-seating the card or issuing raw setpci writes that can hang the device. None of these are reversible in the way a disk-fill test is reversible, and a hung GPU on a fleet we were about to hand back costs more than the test is worth.
So for those five we exercise the classification logic with fixtures (for example, the XID rule's mapping of a code to NVIDIA's published severity table, or the NVLink rule's per-link down-state predicate) and we tell you that is what we did. The FIX prose for the forensic rules (XID, uncorrected ECC) correctly directs the operator to capture nvidia-bug-report.sh and dmesg before touching anything, because the first job on a P0 GPU fault is preserving evidence, not clearing the alert.
The A16 that was actually two A16s
Our own inventory described the A16 host as "a 4-GPU board." When we actually queried it, nvidia-smi and our API both reported eight dies across two A16 boards, uniform vbios 94.07.62.00.AD across all eight. Not a bug, just a reminder that the only inventory you can trust is the one the hardware reports.
The A16 was also the most useful host, because it throttles on its own. At any given snapshot, between two and four of its eight dies showed sw_power_cap active, and the active set shifted between snapshots as dies entered and left power-gated state. That gave us a live, ongoing, non-induced power-cap-throttling condition to validate against, which we preserved as ground truth rather than clearing.
The thing we most wanted to confirm was per-die deduplication. A naive parser does one of two wrong things: it aggregates eight dies into one host-level alert and hides which die is throttling, or it over-emits and reports a row per die per snapshot even when the die is fine. Ours did neither. Across the event window, fires landed on six of eight distinct PCI BDFs, and at the validation moment the host showed exactly three active alerts, one row per currently-throttling die, each carrying its own gpu_uuid, pci_bdf, power_draw_w, power_limit_w and throttle-reason set. The campaign also confirmed a recent field-name correction (the throttle-reason key hw_power_brake_slowdown) works on driver 550.163.01, by running the rule's own quick_check command over SSH and diffing the output.
Thermal load on the L4: the rule that correctly stayed quiet
The L4 is our highest-fidelity card because it matches our production inference host. We ran a sustained thermal load on it: a user-space PyTorch burn loop (repeated 8192x8192 matrix multiplies with a dependency chain to defeat dead-code elimination), 100% utilization for about six minutes. No power-limit change, no fan-curve modification, no thermal-protection bypass. Purely passive observation of where the temperature settled.
It settled at 67 degrees C. The thermal-critical threshold is 90 C absolute, with hardware slowdown around 86 C. The card never came close, so gpu_thermal_critical correctly did not fire. That is the result you want from a thermal rule under a healthy heavy workload: silence. A rule that fired here would be a false positive, and a GPU monitoring tool that cries wolf every time someone runs a real training job is worse than no tool.
A practical aside that will save you time: the L4 box had docker but no NVIDIA container runtime, so the usual containerized burn tools failed at CDI vendor discovery. The reversible path that worked was a throwaway Python venv with the CUDA-bundled PyTorch wheel, which only needs the host libcuda.so. Worth knowing if you ever need to load-test a GPU box that was set up for inference, not for CUDA development.
Driver drift, and the limits of per-snapshot detection
The driver/firmware-drift rule is the clearest example of a rule that is correct precisely because it stays quiet. It fires only when two GPUs of the same model on the same host report different vbios versions, which is a real and nasty failure mode on multi-GPU boxes after a partial firmware update. On the A16's eight dies the vbios was uniform, so it did not fire. On the single-GPU L4 and RTX A4000 it cannot fire at all (one GPU has nothing to disagree with), and the rule returns early on any host with fewer than two GPUs. We validated all three of those as correct proofs-of-no-fire.
It is also a useful place to be honest about a limit. This rule detects drift within a single host, because that is what a per-snapshot evaluator can see. Cross-host fleet-wide drift, the same model running different firmware on different machines, is a different and harder problem that needs a cross-snapshot aggregation primitive we have not built yet. We would rather ship the within-host check that works than imply a fleet-wide guarantee we cannot currently make.
What this means if you run GPUs
The summary we are comfortable putting our name to: the power-cap-throttling rule is fleet-tested on a real multi-die A16 with confirmed per-die behavior; the thermal rule is validated under a real sustained load on the production-equivalent L4 and correctly stays quiet below threshold; the driver-drift rule is validated as a correct proof-of-no-fire across all three cards. The five fault-injection rules are validated against fixtures that match the real telemetry shape, and we label them that way rather than claiming an induction we did not perform.
That distinction, fleet-tested versus fixture-tested, is the entire point. A monitoring vendor that says "GPU monitoring, fully tested" without telling you that nobody can safely create a real uncorrected-ECC error on a production card is either being loose with the word "tested" or does not run GPUs themselves. We do, and this is the honest map.
The eight GPU rules and what each one checks are public at /docs/rules, and you can see the GPU panel itself on a sample A16 host in the live demo.