When a Phase 1 audit changed our hypothesis
A small story about how spending an hour mapping the actual problem before writing any code saved us from fixing the wrong thing.
We had a bug to fix. A server in our validation fleet was reporting "IPMI: Not detected" while simultaneously displaying ECC error counts on the same page. Two pieces of data on one screen, telling opposite stories about the same hardware.
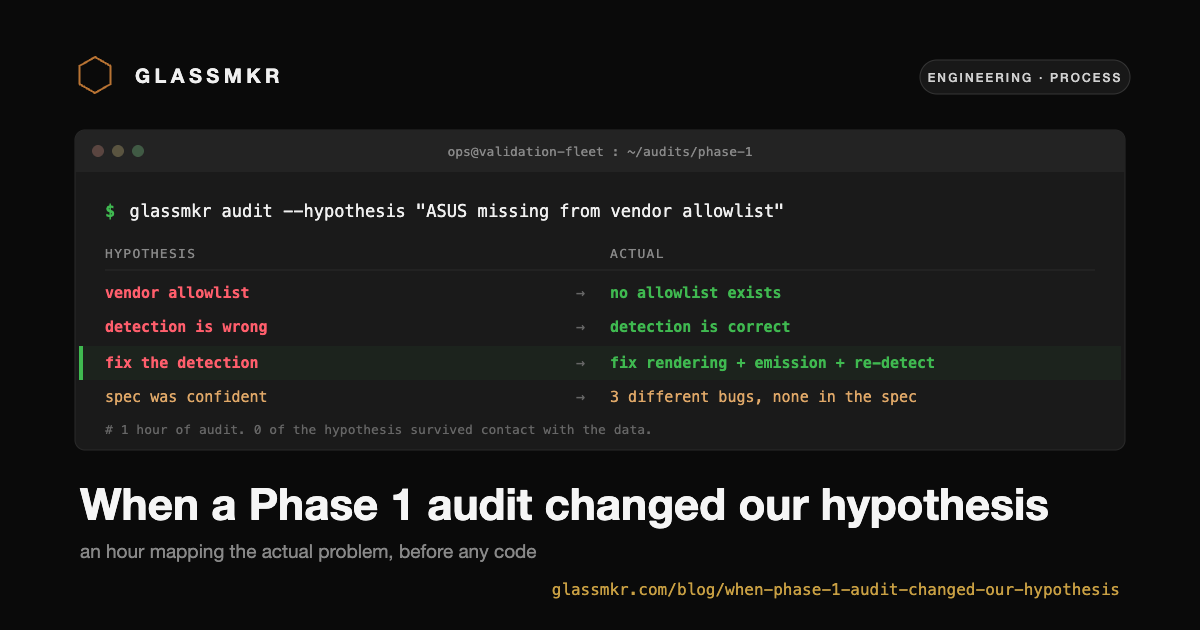
The obvious hypothesis: our detection logic is wrong for this vendor.
We almost wrote that fix immediately. Then we ran a Phase 1 audit instead. The audit changed what we thought was wrong.
The contradicting screens
A user on our dashboard would have seen this on the server detail page for our ASUS RS700-E10-RS4U test box:
IPMI: Not detected
ECC Errors: Correctable: 0, Uncorrectable: 0Two statements on one card. One says we cannot talk to the BMC. The other quotes numbers that, in the rest of the product, come from the BMC.
A customer reading this would land in one of three places. They might assume the dashboard is broken in a small way and ignore both numbers. They might assume the monitoring layer is unreliable in general and reduce their trust in everything else we surface. Or they might assume we have a stub somewhere that emits "0, 0" by default and we never thought to ask whether the data was real. The third reading is the worst, because it is the correct one.
We had a fix queued up. We were ready to start coding.
The wrong fix we almost shipped
The initial spec said the detection logic had a vendor-string allowlist somewhere, ASUS was not in the list, and the fix was to switch to capability-based detection. Vendor allowlists are a familiar bug shape on cross-vendor hardware code; we had hit similar shapes before. The story sounded right.
It also fit the visible symptom: one specific vendor reports "Not detected", the others report fine, therefore the allowlist is at fault. The conclusion flowed naturally from the symptom.
We almost wrote that fix immediately.
Two things stopped us. One was a habit we had been building for a few months: before code on any non-trivial fix, do a Phase 1 audit. Map what is actually broken across all systems in the fleet, not just the one you noticed. The other was a small unease: if it really was a vendor allowlist, why had we not seen the issue earlier on the other vendors that should also be missing from the list?
The audit was meant to take an hour. We expected it to confirm the hypothesis and validate the spec. We were going to ship the same afternoon.
What the audit found
The audit produced three findings, none of which matched the original hypothesis.
Finding 1: there was no vendor allowlist. Detection was already capability-based. The code did three probes in order: stat /dev/ipmi0, run ipmitool -V, and if both succeeded, mark IPMI as available. No vendor strings were involved anywhere in the detection path. The hypothesis was wrong from the start. We would have spent a day refactoring a vendor allowlist that did not exist.
Finding 2: the detection logic was actually correct. The box reporting "Not detected" had ipmitool simply not installed. The agent's detection chain found /dev/ipmi0, did not find ipmitool, and recorded detection.reason: "no_ipmitool_binary". That is honest behavior. The bug was downstream. Our collection path emitted stub ecc_errors: { correctable: 0, uncorrectable: 0 } whenever detection failed, and our dashboard rendered those stubs as if they were real measurements. The two contradicting screens were not a detection bug; they were a rendering layer trusting zeros that were never measurements.
Finding 3: detection ran once at startup and cached forever. A customer who installed ipmitool after Crucible started would see no change until they restarted the agent. This is the exact shape of a real incident we had hit weeks earlier on a different box, where a missing package was fixed in five minutes but the dashboard kept lying for a day because nobody thought to restart the daemon.
So the actual bug was not "detection is wrong about ASUS." It was three problems stacked together: collection emits fake data when detection fails, rendering treats fake data as real, and detection never re-checks. Three different fixes, none of them what the original spec said.
If we had shipped the original spec, we would have refactored a non-existent vendor allowlist and missed all three real problems.
What we shipped
Four fixes, all in roughly a day:
- Stop emitting stub zeros. When detection fails, the agent now emits
nullfor ECC counters and SEL entry counts. The Dashboard's snapshot schema was updated to accept both the newnullshape and the legacy stub-zero shape, so older agents on the rollback path keep working during the upgrade window. - Render
nullas "no signal". The dashboard now distinguishes "the BMC said zero" from "we could not ask the BMC". The ECC block displaysno signal (BMC not probed)instead of0 / 0when the agent could not probe. - Surface the detection reason. Crucible already emitted a structured
detection.reasonfield with four possible values (no_ipmitool_binary,permission_denied,no_bmc_device,execution_failed). The Dashboard now reads it and appends a one-line, human-readable explanation next to "IPMI: Not detected" on the header. A user looking at the box now sees: "IPMI: Not detected (ipmitool not installed)." That is enough information to fix the problem in one minute, no support ticket. - Re-detect every hour. Detection is no longer cached forever. Customers who install
ipmitoolafter the agent started do not need to restart anything; the next hourly re-check picks up the change and the dashboard flips on the following ingest.
Plus a new self-diagnosis subcommand: glassmkr-crucible doctor ipmi runs the same probes the agent uses internally and prints actionable guidance per failure mode. For no_ipmitool_binary it gives the per-distro install command. For permission_denied it points at the systemd unit's User= directive. For no_bmc_device it suggests modprobe ipmi_si ipmi_devintf or accepting that this host has no BMC. For execution_failed it gives a one-liner reproducer and a deliberate warning against mc reset cold on a remote machine without vendor confirmation.
Total work, including the audit hour: about a day. If we had shipped the original spec, we would have spent the same day building something irrelevant to the actual bug.
Why Phase 1 audits are worth the hour
When a bug has more than one possible explanation, the cheapest move is to enumerate the explanations and check which is true before writing code. An hour of audit can save a week of building the wrong thing.
The audit format that worked for us:
- For each candidate explanation, decide what data would prove or disprove it.
- Run the data collection on the real systems, not just the one that surfaced the symptom.
- Compare the findings against the hypothesis explicitly. Write down the comparison.
- If the data contradicts the hypothesis, update the spec before writing code.
The audit will sometimes confirm the original hypothesis. That is fine. An hour to validate a spec is cheap insurance, and you go into the implementation with a sharper picture of the edges.
But sometimes the audit changes the diagnosis entirely, like ours did. That is when the hour pays for itself many times over. We saved a day of refactor, surfaced two bugs we did not know we had, and shipped something the customer can actually use.
The lesson is not "be slower." The lesson is "be honest about which step is hypothesis and which step is verified." Code written from a verified diagnosis is faster to write and likelier to be correct. Code written from an unverified diagnosis is often the most expensive kind of code: the kind that ships, looks fine in review, and does not solve the problem.
The audit also surfaced a PSU monitoring bug across our entire fleet that we had silently for months. That is a separate story.