We used an AI as a controlled probe of our alert documentation
We run a small fleet of bare metal servers to validate Glassmkr against real hardware diversity. Seven boxes across four vendors, three operating system families, and a range of generations from 2017 to 2024. The fleet does what fleets do over time: it accumulates alerts.
Last week we had 35 active alerts firing on the dashboard. Most were the kind of routine drift that a small operator would address in an afternoon: kernel updates pending, security patches available, automatic updates not configured. The dashboard had been telling us what to do for weeks. We had been doing nothing.
We decided to do something useful with the backlog. Instead of fixing the alerts ourselves, we ran an experiment: have a coding agent attempt to fix every alert, but with one critical constraint.
The constraint
The agent could use:
- Each alert rule's section in our
/docs/alertspage - The
fix_commandsfield returned in the alert's evidence JSON - Any text linked from our own docs
- The journal output the alert pointed at
It could not use:
- General Linux administration knowledge from its training data
- Web search for vendor documentation outside what we linked to
- Common-sense ops moves not suggested by us
The point of the constraint is to test our documentation, not the model's ability. Without the constraint, the agent would solve everything by reaching for its training data, and we would learn nothing about our docs. With the constraint, every gap in our guidance becomes visible. The agent either resolves the alert using only what we said, or it does not.
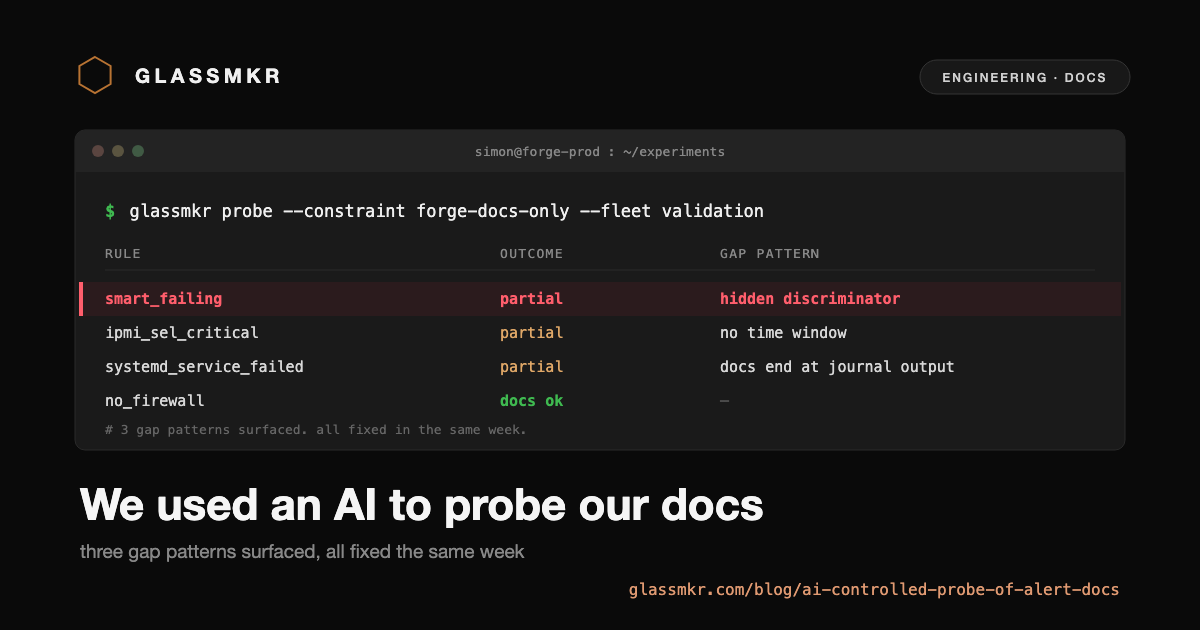
We ran this against nine boxes producing 35 active alerts. After deduplicating by rule type, that came to 10 distinct rule types covering kernel updates, firewall configuration, SSH hardening, security patches, automatic updates, systemd service failures, IPMI SEL events, interface errors, SMART failures, and kernel vulnerabilities.
What we found
Most rules were fine. The agent attempted resolution on three of the riskiest types (where applying the fix had real consequences) and reviewed the others for guidance quality. Four of the ten rule types had no actionable gap. Three were trivially resolvable through Dashboard's documented commands. The remaining three had specific, fixable gaps in either the evidence shape or the documentation.
These three are worth describing in detail because each represents a different failure mode.
Pattern 1: the alert and the evidence disagreed
On one box, smart_failing was firing with severity critical. The agent read the evidence and found health: "PASSED". From a customer's view, the alert said the drive was failing while the evidence said it had passed its health check. There was no third field explaining the contradiction.
The rule actually fires on multiple independent SMART thresholds: reallocated sector count above a vendor threshold, pending sector count growth, offline uncorrectable count. Any one of these can fire the rule. The evidence shape simply did not name which condition had fired.
The fix was a one-line evaluator change: emit a triggering_signals array that explicitly names every condition that tripped. On the same box after the fix, the alert displayed clearly:
"triggering_signals": [
{ "attribute": "reallocated_sectors", "observed": 1, "expected": 0 }
]One sector remapped on the Crucial MX300. Real signal, low severity, immediately legible.
Pattern 2: the alert fired on history
On our production services-1 host, ipmi_sel_critical was firing on Power Supply AC events from November 2024. The events were paired Asserted/Deasserted entries, meaning the BMC itself had observed the supply drop and recover. By May 2026, the supplies had been operating cleanly for fifteen months. The alert had been firing throughout.
The rule had no time-window mechanism. Once a critical event entered the System Event Log, the rule fired forever, even on year-old transients. The evidence did not expose event timestamps, so a customer reading the dashboard had no way to know whether the incident was current or ancient without dropping to shell.
The fix was twofold. Add timestamps to each event in the critical_events[] evidence array. Add a configurable time window to the rule itself, default 30 days, with per-server overrides for noisy hosts. After the fix shipped, the services-1 alert auto-resolved at the next ingest cycle: the year-old events fell outside the new window. No customer action needed.
Pattern 3: the alert pointed at the problem but not the fix
On a third box, systemd_service_failed was firing on fail2ban. The agent followed our four-step guidance: check status, read the journal, attempt restart, check status again. The first three steps worked. The journal showed the actual problem: Have not found any log file for sshd jail. The fourth step (restart) failed because the underlying config issue was unchanged.
Our docs ended at this point with the suggestion to "check configuration and dependencies." That is exactly where customer self-service breaks. The journal told the truth. We needed to bridge from the journal output to a fix.
The fix was operational, not documentary: we changed Crucible to include the last few journal lines from the failing unit directly in the alert evidence. Customers no longer need to SSH to see what failed. The alert evidence on that box now displays the Have not found any log file for sshd jail error verbatim. The bridge to a fix is shorter.
The cross-cutting finding
The three gaps look different, but they share a shape: in each case, the evidence the rule already had access to was richer than the evidence the customer saw. The fix in all three cases was to surface more of what we already knew.
This is the consistent gap pattern. Our /docs/alerts pages tell customers in general terms what an alert means. The evidence JSON tells them, specifically, what the rule observed. The two were diverging. Customers reading the alert evidence in our dashboard got better guidance than customers reading our docs page.
We also noticed a softer version of the same pattern in the rules where the agent successfully resolved alerts. For interface_errors, our fix_commands field includes a firewall-vs-NIC disambiguation check that our /docs/alerts page does not mention. For ssh_root_password, our fix_commands field includes a key-access verification probe that our docs page does not mention. The richer guidance was hiding in the alert payload itself.
What we shipped
Within the same week we shipped three evaluator changes and a documentation audit. The evidence shape improvements landed first because they are higher leverage: every customer reading any alert benefits immediately. The docs audit pass landed second to close the parity gap between /docs/alerts and fix_commands.
We did not add an "Actionable steps" section to each rule because fix_commands already serves that purpose. The bug was that /docs/alerts did not reflect it.
The methodology, separately
The constraint that made this experiment work is worth pulling out. Without it, the experiment would have measured an LLM's general Linux competence, which is not interesting because the answer is "high enough for most things." With it, the experiment measured whether our own guidance is complete enough for self-service, which is exactly the question that matters for customers.
Anyone running a similar exercise on their own infrastructure should adopt the same constraint. Forbid the agent from using its training data on the domain. Force it to use only your product's documented guidance. Each failure point is a gap that real customers will also hit. The advantage of running it through an AI is speed: the experiment took about an hour of wall-clock time. The advantage of using your own product is honesty: every gap surfaced is a real one.
One note on tooling: we used an external coding agent (Claude Code) for this experiment because forbidding training-data use is cleaner to enforce against an external agent than against our own production deployment. The experiment ran on our validation fleet, not against any customer infrastructure. Customer telemetry from Glassmkr accounts continues to be analyzed by our Gemma 4 26B running on a dedicated L4 GPU in Amsterdam, and never leaves the Glassmkr stack.
We are doing this again in a month. The list of remaining work has not gone empty.